This assignment is designed to apply knowledge about regression analysis to real world scenarios.
Skills acquired and demonstrated in this assignment:
- Running a regression in SPSS
- Interpreting regression output and predicting results given data
- Manupulating data in Excel and Join to ArcGIS
- Mapping standardized residuals in ArcGIS
- Connecting statistics and spatial outputs
In Part 1, a study on crime rates and poverty was conducted for Town X. A local news station got a hold of some data and made a claim that as the number of kids that get free lunches increases, so does crime. The goal is to run a regression equation with the given data to determine if the claim is correct. Then a new area of town was identified as having a 23.5% free lunch level, and the corresponding crime rate must be calculated.
In Part 2, the City of Portland is concerned about adequate responses to 911 calls. They are curious what factors might provide explanations as to where the most calls come from. A company is interested in building a new hospital and they are wondering how large an ER to build and the best place to build it. While an answer for the size of the ER can't be given using these methods, some ideas as to the influences related to more or less calls and possibly where to build the hospital can be provided. The following data has been provided:
-Calls (number of 911 calls per census tract)
-Jobs
-Renters
-LowEduc (number of people with no High School degree)
-AlcoholX (alcohol sales)
-Unemployed (number of unemployed people)
-ForgnBorn (foreign born population)
-Median Income
-CollGrads (number of college grads)
Step 1: Running Single Regression in SPSS
Three independent variables must be chosen to be analyzed using regressional analysis, with Calls being the dependent variable. All information regarding relationships between these variables must be explained.
A map of the number of 911 calls per Census Tract must be created along with a standardized residual map of the variable found with the largest R Square value.
Step 3: Multiple Regression
A multiple regression report must be run with all the variables listed above and determine if multicollinearity is present. Then a step wise approach must be run with the results explained.
Important background information:
Regression Analysis- a statistical tool used to investigate the relationship between two variables.
-it seeks to predict the effect of one variable to another, but unlike correlation it investigates causation.
-uses 2 variables, the independent variable (x) and the dependent variable (y).
Formula: y = a + bx
a = the constant
b = regression coefficient (slope). Shows 1 unit of change in the dependent variable. Gives direction of relationship between the two variables.
Ordinary Least Squares (OLS)- fitting a straight line through a set of points in such a way that the sum of the squared vertical distances from the observed points to the fitted line is minimized. It is a trendline.
Coefficient of Determination (R Square)- illustrates how much x explains y.
-ranges from 0-1. (0 is no strength and 1 is very strong)
Residual- the amount of deviation of each point from the best fit line.
-represents the difference between the actual and predicted value of y.
Standard Error of the Estimate (SEE)- the sum of the standard deviation of the residuals.
-another measurement of the accuracy of the regression line.
-smaller SEE indicates more accurate prediction.
-impacted by large outliers
Multiple Regression- uses more than one independent variable to explain the dependent variable.
-most widely used statistical method.
-shows relationships between variables as a plane (3D).
Formula: y = a + B1X1 + B2X2 ... BnXn
a = the constant
Bn = partial slope coefficients. Shows the change in y associated with a one unit increase of X1 when the other independent variables are held constant. Values for each Bn variable are the sum of squared deviations (residuals) from all points in order to minimize the distance from the plane.
Beta or Standardized Regression Coefficient- the average amount the dependent variable increases when the independent variable increases one deviation and the other independent variables are held constant.
Formula: Beta = bi(Sxi/Sy)
bi = B value
Sxi = the standard deviation of the particular independent variable
Sy = standard deviation of the dependent variable
Step Wise Regression- examines the contribution of each variable to the equation and adds the variable with greatest incremental contribution first. Basically it sees which variables are the best ones to explain the dependent variable. It will exclude variables that do not improve the equation.
Multicollinearity- occurs when two independent variables are highly correlated with one another. Tends to make some independent variables not significant when they probably are significant. Indicators include: Eigen values, condition index, and variance properties.
Eigen Values- conceptually represents the amount of variance accounted for. Eigen values close to 0 mean multicollinearity may be present.
Condition Index- high condition indexes (over 30) are flags for multicollinearity.
Variance Properties (VP)- values that show which variables may be causing the problems. Values close to 1 are the problem. Eliminating the variable with the highest VP may fix problems.
Tolerence- MC exists if tolerance is below 0.1.
Variance Inflation Factors (VIF)- MC exists if VIF is greater than 10 or all factors on average are greater than 1.
Methods
Part 1
In SPSS, an Excel file was brought in and used to run a regression analysis. The results were analyzed to determine if the claim was correct. The new area of town statistic was entered into the regression equation to determine the corresponding crime rate.
Part 2
Step 1: Running Single Regression in SPSS
Using Calls as the dependent variable, a regression analysis was run individually for these independent variables: Unemployed, Foreign Born Population, and Alcohol Sales. The results of each of these were used to analyze the relationships that exist between these variables and 911 calls.
Step 2: Choropleth Map and Residual Map
Using ArcMap, two maps were made: calls per census tract choropleth map and a map of the variable found with the largest R Square value, which was Foreign Born Population. The residual shapefile was created by following "spatial statistics tool" - "modeling spatial relationships" - "ordinary least squares". These maps were then used to make connections between the data and a spatial context.
Step 3: Multiple Regression in SPSS
A multiple regression report was run with all the variables listed above. Collinearity Diagnostics were turned on to determine if multicollinearity was present, and the results of the relationships were further analyzed. Next a Stepwise approach was taken to put the variables in order from most to least important and the results were used to analyze the relationships present. The most important variables were then mapped using ArcMap.
Results
Part 1
 |
| Figure 1: Results from the regression analysis performed to test the claim of the local news. |
In this scenario, the number of kids that get free lunch is
the independent variable (x) and the crime rate is the dependent variable
(y). The corresponding formula for the
regression would be y = 21.819 + 1.685x.
What the regression statistics tells us is that there is a relationship
between the number of kids that get free lunch and the crime rate, however the
relationship is very weak. The R Square
value (ranges from 0-1) is low at 0.173.
Though we would reject the null hypothesis and say a relationship exists
because the significance level is .005, which is below .01, it only suggests
there is not much more than a hint of more kids getting free lunch causing
crime rates to rise.
Based on the dataset, for the new area of town having a
23.5% free lunch, the corresponding crime rate would be 61.4. This was calculated by using 23.5 as x in the
formula: y = 21.819 + 1.685(23.5). Confidence
in this value is not very high however, because the Std. Error of the Estimate
is high at 96.6072. This means the data
is not tightly distributed along the trend line, there is a lot of
residual.
Part 2
Step 1: Running Single Regression in SPSS
 |
| Figure 2: Regression analysis results with Unemployed as the independent variable. |
 |
| Figure 3: Regression analysis with Foreign Born Population as the independent variable. |
 |
| Figure 4: Regression analysis results with Alcohol Sales as the independent variable. |
Step 2: Choropleth Map and Residual Map
 |
| Figure 5: Choropleth map of 911 calls per census tract in Portland. |
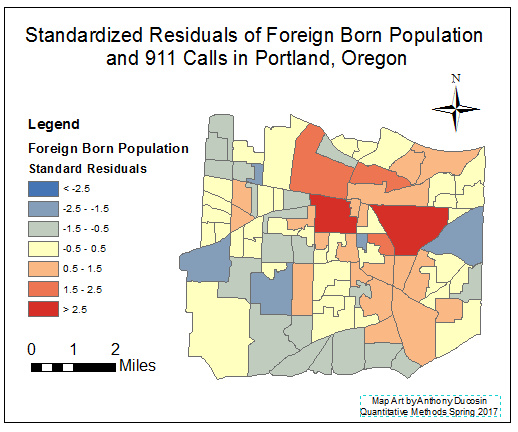 |
| Figure 6: Residual map with Foreign Born Population as the independent variable and 911 Calls as the dependent variable. |
Step 3: Multiple Regression
 |
| Figure 7: Multiple regression analysis results using all the variables listed above as independent variables with Calls as the dependent variable. |

 |
| Figure 8: Results from the stepwise regression analysis showing Renters, Low Education, and Jobs as the three variables that best explain 911 Calls. |
 |
| Figure 9: Residual map with 911 Calls as the dependent variable and Renters, Low Education, and Jobs as the independent variables. |
Conclusion
Based on the results of the regression analysis' performed for all the variables provided, and the maps created including residuals, a good suggestion for a place to put a hospital would be in the dark red area in the residual map (Figure 9), or in the concentration of red tracts. The stepwise approach indicated that renters, low education, and jobs were the variables that best explained 911 calls. These predictions are not perfect, but they do a fairly good job at explaining where 911 calls come from.
Sources
Maps made in ArcMap
Statistics done in SPSS
No comments:
Post a Comment